Artificial intelligence (AI) can be said to be the hottest topic in the computing field in 2016. The war of manufacturers competing to develop dedicated chips has already started...
For the computing industry, no concept should be more popular than artificial intelligence (AI) in the past 2016. In 2017, experts said that the demand for the artificial intelligence ecosystem will grow more rapidly. The main focus is on the "inference engine" that is more suitable for deep neural networks to find performance and efficiency.
Today's deep learning systems rely on software-defined networks and the enormous computing power generated by massive data learning, and rely on this to achieve the goal; unfortunately, this type of computing configuration is difficult to embed into those computing power, memory capacity and In systems with limited bandwidth (such as cars, drones, and IoT devices).
This brings a new challenge to the industry – how to embed deep neural network computing capabilities into end devices through innovation. Remi El-Ouazzane, chief executive of Movidius, a computer vision processor designer (which has been acquired by Intel), said a few months ago that deploying artificial intelligence at the edge of the network would be a big trend.
When asked why artificial intelligence was “rushed†to the edge of the network, Marc Duranton, an academician of the French Atomic Energy Commission (CEA) architecture, IC design and Embedded Software (Architecture, IC Design and Embedded Software), proposed three reasons: Safety, privacy, and economy; he believes that these three points are important factors driving the industry to process data at the terminal, and the future will generate more "information to convert data into information as soon as possible".
Duranton pointed out that if you want to drive autonomous vehicles, if the goal is safety, those autopilot functions should not rely solely on uninterrupted network connections; for example, old people fall at home, this situation should be on the spot by local monitoring devices. Judging it, considering the privacy factor, this is very important. He added that it is not necessary to collect all the images of 10 cameras in the home and transmit them to trigger an alarm, which also reduces power consumption, cost and data capacity.
AI competition officially launchedIn all respects, chip vendors are already aware of the growth needs of the inference engine; many semiconductor companies, including Movidus (Myriad 2), Mobileye (EyeQ 4 & 5) and Nvidia (Drive PX), are racing to develop low-power A high-performance hardware accelerator that allows machine learning to be performed better in embedded systems.
From the perspective of the actions of these vendors and the development direction of SoC, in the post-smart phone era, the inference engine has gradually become the next target market pursued by semiconductor manufacturers.
Earlier this year, Google introduced the tensor processing unit (TPU), which is a turning point in the industry to actively promote machine learning chip innovation; Google said in the release of the chip, TPU performance per watt compared to the traditional FPGA and GPU It will be a higher level, and it is pointed out that this accelerator has also been applied to the AlphaGo system, which has been popular all over the world at the beginning of this year. But so far Google has not disclosed the specification details of the TPU, nor does it intend to sell the component in the commercial market.
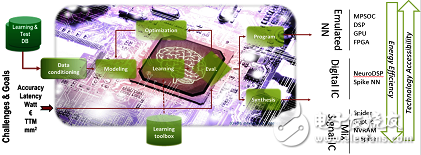
Many SoC practitioners have come to the conclusion from Google's TPU that machine learning requires a customized architecture; but when they design chips for machine learning, they are confused about the architecture of the chip and want to know Is there a tool in the industry to evaluate the performance of deep neural networks (DNN) in different modalities?
Performance assessment tool will be available soonCEA said the organization is ready to explore different hardware architectures for the inference engine. They have developed a software architecture called N2D2 that helps design engineers explore and generate DNN architectures; Duranton points out: "The purpose of our tool development Is to choose the right hardware target for DNN." CEA will release N2D2 open source in the first quarter of 2017.
N2D2 is characterized by not only comparing hardware based on recognition accuracy, but also performing comparisons in terms of processing time, hardware cost, and power consumption; Duranton said, because of the deep learning for different applications, the hardware configuration required The parameters will vary, so the above comparisons are very important. N2D2 provides a performance reference standard for existing CPUs, GPUs, and FPGAs, including multicore and numerous cores.
N2D2 operating principle
Barrier to edge computingCEA has conducted in-depth research on how to extend DNN to edge computing (edge ​​compuTIng); Duranton pointed out that the biggest obstacle is that the "floating point" server solution is not applicable because of power consumption, memory size and latency. Other obstacles include: "Requires a lot of MAC, bandwidth and on-chip memory capacity."
So, using integers (Integers) instead of floating-point operations is the most important issue... Is there anything else? Duranton believes that this proprietary architecture also requires new coding methods, such as "spike coding"; CEA researchers have studied the characteristics of neural networks and found that such networks can tolerate operational errors, making them suitable for use in "Approximate computaTIon".
In this way, even binary coding is not required; and Duranton explains that the benefits are temporal coding such as spike coding, which provides more energy efficient results in edge operations. Spike coding is attractive because of spike coding—or event-based—the system can show how data in the actual nervous system is decoded.
In addition, event-based coding is compatible with dedicated sensors and pre-processing. This extremely similar encoding to the nervous system makes analog and digital mixed signals easier to implement and helps researchers create low-power, small hardware accelerators.
There are other factors that can accelerate the progression of DNN to edge operations; for example, CEA is considering the potential for adjusting the neural network architecture itself to edge computing. Duranton pointed out that people have begun to discuss neural networks using the "SqueezeNet" architecture instead of the "AlexNet" architecture. It is understood that the former requires one-fifth of the parameters required for the same accuracy as the latter; such simple configuration It is critical for edge operations, topology, and reducing the number of MACs.
Duranton believes that the ultimate goal is to convert classic DNN into an "embedded" network.
(To be continued..)
Editor: Judith Cheng
LED Module Indoor Full Color P6 Module Indoor LED Display Module using the newest generation technology, 27777dots per square meter. P6 Module Indoor Full Color with high refresh rate, anti corrosion, anti mildew, anti shock, anti electromagnetic. P6 LED Display Module is one good choice when compare Indoor Full Color LED Display Module. We sincerely invite customers all over the world visit us for cooperation.
P6 Module Indoor,P6 Indoor Led Module,P6 Indoor Led Screen Module,P6 Indoor Led Display Module
Shenzhen Jongsun Electronic Technology Co., Ltd. , https://www.jongsunled.com